
A Template for Clean Domain-Driven Design Architecture

Overview
The purpose of this blog entry is to introduce an architectural template for building web applications which is based upon my interpretation of the Clean DDD and CQRS concepts that I introduced in the previous entry. The information I provide here is guidance only, and I don't claim this to be the definitive approach to building modern applications. It reflects my own personal software development biases and may or may not be suitable to your needs. Once again, I'm operating under the assumption that you fall into a certain category, namely a developer or team of developers working in a startupy-type environment, or a small team within a larger organization. You embrace Agile and lean startup practices, are flexible in your thinking, and focused on continuous improvement and development. Whatever the case, you should always do your homework as well.
To demonstrate this template, I've created a demo application which attempts to solve a (highly contrived) fictional problem for a fake organization. As indicated in the past few entries, you can find the source code to the demo solution here. Feel free to refer to the source code alongside the architectural guidelines I've outlined below.
In developing this template, I studied solutions and tutorials from a handful of experts. As always, I've linked to those resources at the bottom. The experts/resources that this architecture is based on are Jason Taylor, Julie Lerman, Steve Smith, Jimmy Bogard, Matthew Renze, Vladimir Khorikov, Greg Young, Dino Esposito, and finally the Microsoft e-book, .NET Microservices: Architecture for Containerized .NET Applications.
Out of all of these, I'm most in agreement with the Taylor solution, which in turn seems to be heavily influenced by the Microsoft guide. At first, I wanted to give this template some cool name like "Wolverine Architecture," but I didn't want to come off as too presumptuous, so I will just refer to it as "my architectural template" or "my architecture."
Before I dive in, I'd like to list a few more caveats:
- The demo application is NOT complete, as it is in an initial state which is sufficient to demonstrate the concepts I've discussed in this and previous blog entries. It will change and evolve over time as I elaborate on more software development topics. As a matter of fact, at this point the actual "app" isn't even an ASP.NET Core web application—I've started it out using a simple console application standing in for the Presentation layer. Hopefully this will help you to get a good idea of how the various layers and their corresponding components communicate through the stack without being distracted by too many boilerplate details that would have been there had I used an actual web app for the main project. I'll try to tag the source code accordingly, so that each revision can be easily indexed to the blog entries that it pertains to.
- A few key features are currently missing, such as Identity and Security. I'll add those in future posts.
- This architecture represents the stack up to the Persistence layer. I'm not going to touch on the UI yet.
- I don't agree with the above references on all points. It's okay to disagree with the experts (although, if you are going to adopt a heretical stance, be well-prepared to defend your choice). I'll try to clarify my reasoning in areas in which I deviate from their approaches.
First, the Use Case
A company would like to have a comprehensive, business-centric application to manage various functions in the organization.
- They would like to automate processes which belong to the various business units of the organization—Human Resources, Accounting, etc. For example, they need to track payroll at a basic level, and they need a seamless way to onboard or offboard employees through the Manager of HR.
- They need different adjunct functionalities, like tracking paid time off (PTO) time available, which will be handled through the HR side as well.
- The business will almost certainly request additional features in the future as the application grows and they have time to interact with it, elucidating more business requirements.
I've been instructed to build an enterprise solution on the .NET Core stack and deploy it to the Azure cloud. Starting out, the system will simply handle basic HR and Accounting, but it MUST be able to grow to accommodate more complex business functions, such as those managed by Operations, or even the executive team themselves. At the outset, I'm only allowed to use a single relational database as the data store, which will also be in the cloud. Additionally, I've been told by the CIO that the Accounting logic will be coded and maintained by a separate team (maybe even a single individual). She tells me this is for political technical reasons. OK, those are my orders. Time to get to work.
A Template for Business-Focused Web Applications in the Microsoft Cloud
Code-Level Conventions
As stated in blog entry 4, I generally follow the conventions from Framework Design Guidelines. Once again, I highly, highly recommend that you use a tool like CodeMaid or something similar to automatically clean up and organize your files for you. You can customize it to organize them the way you want. Here are some specifics:
- Pascal case is used for classes names, method names, properties and so on.
- Parameter names, private fields, etc. are camel case.
- Underscores are never used, except in method names for unit tests. I never prefix private fields with underscores.
- SCREAMING_CASE is never used.
- While Hungarian notation is not allowed, certain conventions which might resemble it are okay, such as MyCoolController, MyAwesomeVm, UpdateSomethingCommand, etc. In other words, using suffixes. Those are generally okay.
- I mentioned this in a previous post but here it is again. In recent years there has been a small yet fervent movement to stop prefixing interfaces with "I" because technically it is a vestige of Hungarian notation. DON'T DO THIS. Interfaces should be prefixed with "I" because the distinction between them and other types is so important that their names themselves should express this. If you have any doubts, just look at the source code for the various official Microsoft .NET Core packages. What do they do? (When in doubt, emulate the pros).
- I arrange my code files this way, top to bottom:
- Fields/constants
- Properties/indexers
- Constructors
- Methods
- Nested classes
- Within each of the above categories I arrange members based upon access modifier in the following order:
- Public
- Internal
- Protected
- Private
Basic Solution Organization
These are guidelines for organizing the solution into files and projects:
- There should be one class/enum/interface per source code file. This one drives me nuts. I've encountered solutions in which there are five or six different classes in a single file along with a bunch of enums and other nonsense. However, there is an exception to this rule, which you can see in the demo application: I've nested the handler classes for commands/queries inside the command/query classes themselves. The reason for this is simple, which is that user code doesn't need to call them directly. Remember, we are relying on MediatR to perform the dispatch to handler methods.
- Project names, folder names, and namespace names should all align. It drives me crazy when I encounter a solution in which there is a folder called "Foo" and the corresponding namespace for classes in that folder is "Bar." Don't do this. Names of everything should align, so that if decide you need to take a folder full of classes and put it into its own project, the namespaces don't break. This idea, which I'll tentatively call the "Project/Folder/Namespace Fungibility principle" is important, because as the solution grows it gives us the flexibility to refactor it easily and move different sections of the architecture into separate microservices. To put it simply, Project Name = Folder Name = Namespace. Do this, and your solutions will be much easier to refactor.
- Related to the above point is the naming of projects themselves. A good guideline is <Company>.<Solution>.<Layer>.<Bounded context or other detail>. Alternatively, you can use <Solution>.<Layer>.<BC/detail> or whatever. Just be consistent.
- I recommend keeping your project structure flat (for the most part). This means not hiding projects in some nested folder somewhere, which makes them difficult to find.
External Dependencies
This is a list of third-party toolkits, libraries, and NuGet packages that the solution depends upon. This is not comprehensive, and more will be added as the solution grows over time.
- MediatR, by Jimmy Bogard - Used in both Domain layer and Application layer. This is a really powerful package and is the special sauce that brings everything together. As stated in the previous entry, MediatR facilitates a simple, elegant CQRS implementation.
- Entity Framework Core - Microsoft's ORM. Used almost exclusively inside CQRS commands to update the database and sometimes to perform simple queries against it.
- Dapper - A powerful and efficient micro-ORM which allows us to write flexible queries which translate well into DTO/view models. Used on the query side of the stack to return query results by projecting complex SQL queries into 1NF view models.
- FluentValidation - Plugs nicely into MediatR and allows for validation of commands that are sent down the stack before they hit the Domain layer.
- Mapster - A fast and intuitive object mapping library which assists in mapping view models and persistence models to/from domain models. Alternatively, you could use AutoMapper, also by Jimmy Bogard, but at this time I prefer Mapster because it's faster and the usage is slightly more intuitive.
- Serlilog - A powerful logging library which sits on top of the base .NET Core logging infrastructure.
Logical Organization of the Solution
When working with this or any other architecture, I strive to produce solutions that are neatly organized and easy to navigate. A great principle to follow in this regard is Screaming Architecture (The architecture should scream the intent of the system!), which is another Uncle Bob-ism. Starting from this, let's discuss for a minute component organization and functional organization, which are two distinct methodologies for organizing classes, interfaces, components, and other objects together inside a software solution.
Component Organization
Under component organization, classes, interfaces and other objects are grouped together in folders or projects based upon their category, or what they represent—e.g. Controllers, Views, so on. The underlying concept here is categorical cohesion, which simply means that entities of the same classification or category should go together. Imagine grouping baseball players from a baseball league. In this way, all third basemen from all teams would go together into one group, pitchers in another, and so on.
This is the default for most solutions in .NET, especially MVC solutions. At first, this seems easier to grasp but has its drawbacks. As the solution grows, you may find yourself "jumping around" more to find dependencies for different components. I've certainly found this to be the case with most legacy systems I've worked on in corporate environments, in which F12, Ctrl-F12, and Ctrl-Q become my best friends.

These are all the same thing?
Functional Organization
On the other hand, functional organization is based upon the idea of spatial locality: it is more efficient to keep items that are often used together near each other. The underlying concept is functional cohesion, which means that entities which work toward the same goal or purpose should go together. Going back to the baseball analogy, this would simply imply that players from each team should go together, regardless of their positions, because they play together and operate as a functional unit on that team.
As applied to a .NET software solution, classes and other objects are grouped together in folders or projects based upon their use case, or what purpose they serve—e.g. RegisterOrUpdateEmployee, GetPaidTimeOffPolicyList, etc. The benefit to this approach is that it's easier to navigate the solution, especially as it grows, and it helps you to maintain a high level of cohesion around different use cases of the system. Some of the downsides to this are that you might break from framework conventions, lose automatic scaffolding from certain tools, and so on. Personally, I think it's worth the cost. As an aside, it's worth noting that Angular uses functional organization by default, so this isn't a totally radical methodology.

These all work well together.
In my architecture I use functional organization to the greatest extent possible, where it makes sense. Once again, the 80/20 rule (Pareto principle) applies. In situations where it doesn't make sense, I fall back to component organization. In Renze's demo solution he mixes unit test classes into the same folders as the classes under test within the application projects. DON'T EVER DO THIS. Unit tests are a different animal, and they belong in their own projects. Once again, principles and practices are guidance, general rules to follow, and as the character Morpheus states in the Matrix, "some of them can be bent, others can be broken."
When applied to the architectural layers of a Clean DDD solution, functional organization looks like this. Layer/grouping:
- Domain - Each domain entity
- Application - Aggregate root corresponding to each use case
- Persistence - Each database table
- Infrastructure - Each functional area of the operating system (file operations, etc.) and/or external resources
- Presentation - Aggregate root corresponding to each screen or web page
- Cross-cutting (Common) - Each cross-cutting concern (Logging, Security, etc.)
The Template
Just as a refresher, here is what the architecture looks like at a high level.
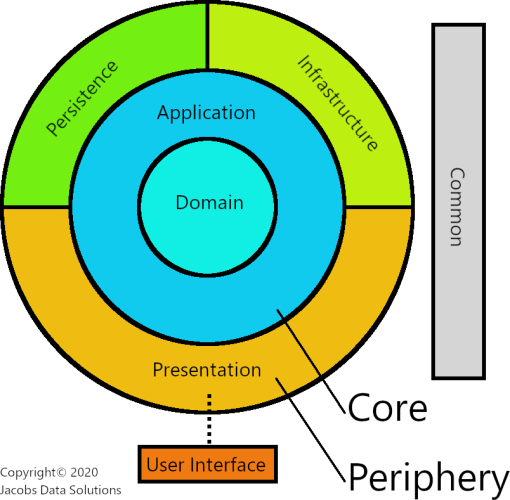
Core Layers
As stated in the previous entry, the core is comprised of the Domain layer and the Application layer. Think of this as the "zone of abstractions and logic".
Domain Layer Organization
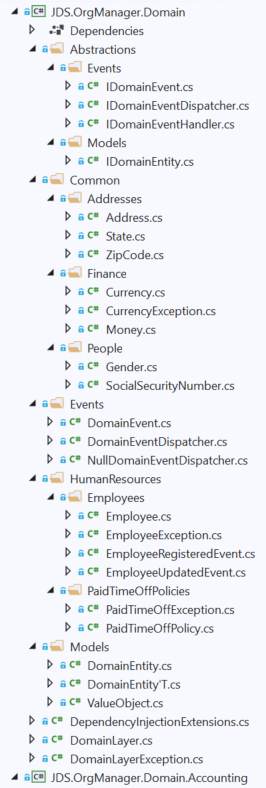
Once again, the Domain Layer should have no knowledge of outside layers, even by proxy (i.e. by exposing interfaces which are implemented by outside layers). It is strictly for business entities and logic.
Key points:
- I start with a single Domain project, in which I create root-level folders that hold base classes corresponding to different key DDD concepts—Models, Events, so on. Additional projects can be added, for instance to separate out bounded contexts, but this is the main one.
- I also have a separate root level folder to house interfaces and other abstractions. I've named this Abstractions, and it's pretty similar to the way that the official .NET Core packages are structured. In fact, at some point in the future we could even separate this into its own project. This is a recurring pattern throughout the layers.
- There is a Common folder at the root level as well, which holds various Domain entities and value objects that don't belong to any particular bounded context. This is essentially a "shared kernel" in DDD-speak. Note that this pattern doesn't just apply to the Domain layer. Anything which cuts across Bounded Contexts goes into a "Common" folder for each layer.
- Additional root level folders exist for each bounded context. In the future, as the solution scales, each one can be broken off into its own project with little refactoring involved, if we continue to abide by the Fungibility principle I stated above. You can see this in the demo app, where I have created a separate Domain project for the Accounting bounded context.
- I studied a few different ValueObject base class implementations and I settled on the one that Taylor's solution and the Microsoft e-book use. In this implementation, child classes must explicitly state which data properties are used for comparison. While this might seem like more effort, I prefer this over reflection-based approaches because the design of each value object should not be taken lightly, and furthermore you don't want to take a performance hit from using reflection in these. See below.
- In general, the Domain layer should have zero reliance on external packages and third-party dependencies. However, if you examine the demo application, you'll see that I put in a hard dependency on MediatR as a means of dispatching domain events. Some may regard this as worthy of a slap on the wrist, but I consider it to be a situation where breaking the rules is acceptable, because trying to abstract away MediatR is simply is not worth the effort, and it wouldn't be hard to remove if the need arose to use a different in-process messaging implementation.
Finally, here are some thoughts on putting persistence abstractions (interfaces) in the domain layer. At least two of the solutions I examined do this. For example, in Khorikov's solution he puts CQRS commands into the Domain layer, and the Microsoft e-book does basically the same thing with repository interfaces.
I don't agree with them. In my architectural template, CQRS commands and queries, and repository interfaces (if you choose to use them) NEVER go into the Domain layer, because they have nothing to do with pure business logic. Persistence logic, even through interfaces, does not belong in there. In this respect, my architecture is more conservative than other Clean DDD solutions—the Domain layer should ONLY be concerned with business logic and interaction among domain entities. The Application layer is the appropriate place to put persistence interfaces because that is the layer of orchestration and coordination.
Application Layer Organization
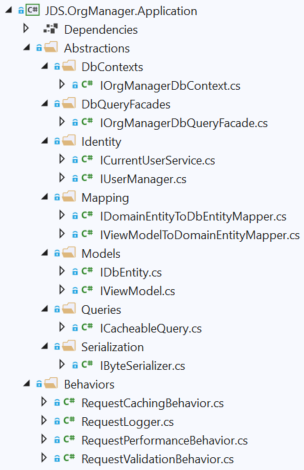
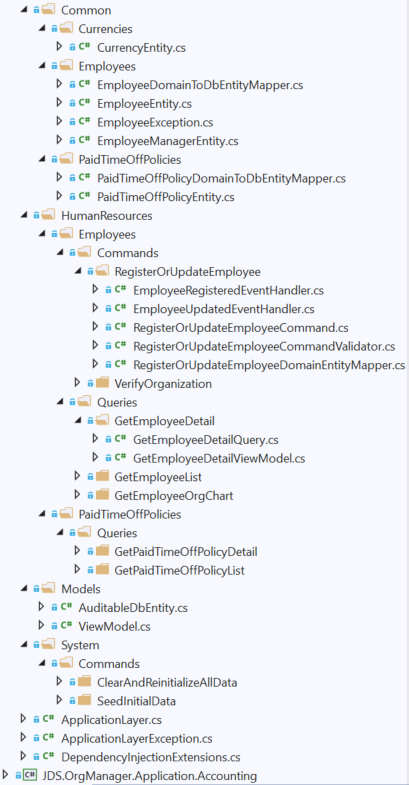
In my opinion, this is the most important layer in the entire architecture, so I'll go into some detail on this.
Key points:
- Just like in the Domain layer, there is an Abstractions root level folder, inside which are subfolders which are broken apart using functional organization. In this case, each subfolder corresponds to different general concerns of the Application layer. This is important because this contains interfaces that higher-level layers, such as Persistence and Infrastructure will implement. This is basically the means by which this layer connects to the higher-level layers: Application layer components receive references to these various interfaces via constructor injection, and the higher-level layers provide the actual concrete implementations. This decoupling is extremely important, as we have now made it easy to mock the Application layer orchestration logic inside unit tests without requiring a connection to an actual database, operating system, etc. This is the Dependency Inversion principle in action. In the demo application there are two interfaces that I want to draw your attention to:
- IOrgManagerDbContext - This is a facade which abstracts away an Entity Framework Core database context for our application data. This will be used almost exclusively on the command side of the stack.
- IOrgManagerDbQueryFacade - This is a facade which abstracts away calls to a micro-ORM called Dapper. This will be used mostly on the query side of the stack, although there's no restriction against using this inside commands, should the need arise.
- There is a Common folder in here as well. Think of it as a higher-level shared kernel. In here are subfolders, each of which corresponds to a separate Entity Framework Core entity, which in turn will map to a database table, since we're using EF code-first. You might be wondering why this is not broken apart by bounded context as well. The reason is simple: we are only targeting one database. As stated earlier, the approach is to build a monolithic application comprised of several projects, which can be broken apart into separate microservices at some later date. When (if) that time comes, we can worry about splitting the data model.
- Also, at the root level there are folders corresponding to different bounded contexts. Just like with the Domain layer, these can be moved into separate projects, should the need arise. Each bounded context folder has subfolders corresponding to each aggregate root. Inside each of these, we've separated our commands from queries. See below on how this could scale, should the need arise to split the stack.
- This layer may reference "helper" libraries such as mappers, internal messaging components (MediatR).
- MediatR + CQRS
- As stated in the previous blog entry, the use of the Mediator pattern along with CQRS is almost a no-brainer. Encapsulating commands/queries as MediatR requests is how we accomplish this.
- We get additional benefits, such as being able to inject cross-cutting concerns into the request pipeline, which is exactly what I've done. The RequestCachingBehavior that I've implemented is a great example of this.
Application Model Classes
Remember from the last entry what I said about view models? To recap, they are models that map to some piece of the UI and are used to communicate back and forth between the UI and the Presentation layer (web API). In this architecture I treat both CQRS commands and the DTOs that are returned from queries as view models. This might strike you as wrong or otherwise violating the Single Responsibility principle, but in this instance it's okay. This is because the task-based orientation of CQRS functionally aligns with the UI, so there's typically a 1:1 correspondence between the models that present information to the user and those that are required/produced by CQRS commands and queries. Furthermore, if there comes a time when the two must be decoupled, there's nothing from stopping us from doing that and putting that mapping logic into the Presentation layer.
The persistence models are a different story... Several the solutions I studied were reusing the EF Core model classes as Domain entities. NO, NO, NO, NO! Even Taylor's solution does this, and his architecture is the closest to mine out of all them. I disagree with virtually all the experts on this. Here's why:
Persistence model classes never quite map perfectly to database tables and queries because of what Greg Young calls an object-relational impedance mismatch. This sounds complicated but it's not. All it means is that databases and programming languages differ in the way they represent data and relationships between entities, so of necessity there always must be some degree of translation going on. More specifically, databases are (traditionally) relational, which means that they are based upon Set Theory. Modern programming frameworks are (often) object-oriented, which means that they are based on Graph Theory. Furthermore, databases have their own data types which are almost always different from the data types used in your programming language of choice, so conversion or even data loss is involved when communicating between the two. If you are using an ORM like Entity Framework, then it will handle this for you. If you are writing straight ADO.NET code, then you have to deal with the pain of mapping between them yourself.
Taking this a step further, domain entities and persistence entities have radically different intents: one is used to model the business and the other is used to store data. The accepted answer from this stack exchange question, by Robert Bräutigam, explains it quite well:
DDD and EF have little to nothing to do with each other.
DDD is a modeling concept. It means to think about the Domain, the Business Requirements, and model those. Especially in the context of object-orientation it means to create a design which mirrors business functions and capabilities.
EF is a persistence technology. It is mainly concerned with data and database records.
These two are sharply divorced. A DDD design may use EF in some form under the hood, but the two should not interact in any other way.
Some interpretations of Domain-Driven Design do advocate data-modeling, and I think this is what your question is about. In this interpretation "Entities" and "Value Objects" are essentially function-less data holders only, and the design concerns itself with what properties these hold and what relation they have between each other. In this context DDD vs. EF may come up.
This interpretation however is flawed, and I would strongly recommend ignoring it altogether.
In conclusion: DDD and EF are not mutually exclusive, they are actually irrelevant to each other, as long as you are doing proper object-modeling and not data-modeling. DDD objects should not in any shape or form be EF artifacts. DDD Entities should not be EF "entities" for example. Inside some business-relevant function, a DDD design might use EF with some related data-objects, but those should be always hidden under a business-relevant behavior-oriented interface.
One solution to avoid getting tangled in this mess is to use mapping. You'll notice that the folders corresponding to different commands/queries have mapper classes which allow you to map from view models to domain models, and back again. Additionally, the folders corresponding to different database tables have mapper classes that allow you to map from persistence entities to domain models, and back again as well. This is the price that we must pay for using a Clean DDD approach because it's important to maintain the decoupling between Domain layer entities and view models/persistence entities. This is the biggest pain point in this architecture, but fortunately that pain can be minimized by using tools such as AutoMapper or Mapster. I've abstracted the mappers for each entity pair behind interfaces, because this makes our solution much more testable and flexible. Dependency injection is used to provide the actual implementations to the command/query classes that need them.
Persistence Entities and Facades
You might be questioning why view models and persistence models are declared in the Application layer instead of Presentation/Persistence. The answer, quite simply, is because the Application layer is doing all the heavy lifting in the system and depends upon them to manipulate the data model inside command handlers, and relay query results back up the stack from inside of query handlers.
Remember from the last entry, in which I talked about the asymmetry of the solution? You can clearly see this in the Application and Persistence layers, in which I'm using two different persistence technologies: Entity Framework Core and Dapper.
- EF Core is Microsoft's ORM for .NET Core. I'm using this on the command/write side of the stack because it makes inserting and updating data to the database much easier. It can also be used for simple queries against the database inside CQRS commands. I've abstracted the EF Core DbContext behind an interface which gets injected into CQRS command handlers.
- Dapper is a lightweight micro-ORM. I'm using this on the query/read side of the stack because it facilitates writing complex database queries without incurring the performance penalties typically associated with ORMs, including EF Core. I've abstracted a few key Dapper methods behind a query facade interface which gets injected into the CQRS query handlers.
You'll notice that the IOrgManagerDbContext and IOrgManagerDbQueryFacade interfaces still allow CQRS command/query handlers to use LINQ and/or straight SQL queries. Aren't these leaky abstractions—i.e. allowing database details into the Application layer? In a sense, yes. Technically I've broken another rule and I'm sure Uncle Bob would yell at me for this. However, I'm of the camp that trying to create a "pure" abstraction that removes ALL knowledge of the underlying data store is not worth the effort, because the paradigms underlying various data stores can be so radically different that it's difficult to keep underlying details from leaking across the interface boundary anyway. What if the underlying data store is a NoSQL database? Or the file system? The Repository pattern attempts to do mitigate this problem, but I'm not a fan of using it in CQRS solutions. Read on.
To Repo, or Not to Repo?
I disagree with a few the experts on the use of the Repository pattern. In my opinion, repositories are an unnecessary abstraction in CQRS solutions—they are trying to solve a problem which doesn't exist, which is the encapsulation of task-based operations into a Unit of Work; the commands themselves already do this. Furthermore, I believe that repositories can tend to sway you toward CRUD-type semantics, whereas CQRS commands (ideally) are unambiguously centered around business tasks. I'm not 100% against repositories, but I think they are more appropriate for CRUD applications.
While it's true that forgoing the use of repositories and writing LINQ/SQL queries directly in the CQRS handlers isn't truly persistence agnostic, it is still flexible enough that we can swap out one database provider for another (in theory). Regarding testability, we still maintain the ability to write unit tests against our CQRS handlers by mocking out the persistence facade interfaces.
Periphery Layers
The periphery is comprised of the Persistence, Infrastructure, and Presentation layers. Think of this as the "zone of implementations and concretes." Honestly, I'm not going to go into great detail with these because they are self-explanatory.
Persistence Layer Organization
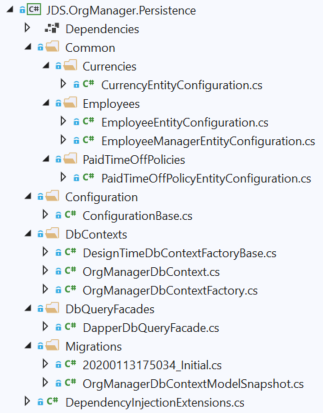
It's important to mention that another benefit to using Entity Framework Core is that it allows us to scaffold our database from the persistence model classes, which can be a huge time saver and result in a clean, robust database schema. That's exactly what I've done, so the EF configuration classes are in here, functionally organized into subfolders, along with the EF code migrations.
The Persistence layer additionally houses the implementations for the EF Core DbContext interface and the Dapper QueryFacade interface.
Infrastructure Layer Organization
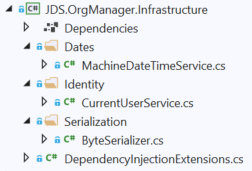
This is very similar to the Persistence layer. The Infrastructure layer contains concrete implementations for abstractions that are defined in the Application layer relating to things like Identity, accessing the file system, external messaging, and so on. Likewise, implementations for abstractions defined in the Common layer should also go in here, a good example being the IDateTime interface, discussed below.
You might be wondering why Identity is in here instead of in the Persistence layer. The reason is that Identity is an entirely separate architectural area from persistence, and there's no reason to assume that user identity will be backed by a DB, as opposed to some third-party identity store accessed through an API (there are dozens out there).
Presentation Layer Organization
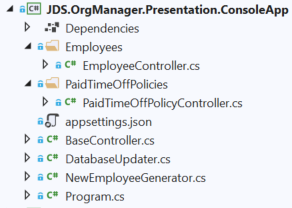
For all intents and purposes the Presentation layer is the top of the stack as far as back end code is concerned. The UI is treated separately. In the finished solution, this will be an ASP.NET Core web API with thin logic inside of it. The only code inside here will be:
- ASP.NET Core boilerplate, to get the web API up and running.
- Controllers, which act as the REST interface that the UI will communicate with.
- High-level components, namely from the Application layer, which get injected into the controllers and called as a consequence of various controller actions. All these components are wired together using an IOC container and dependency injection.
While keeping the Presentation layer decoupled from the Application layer is a must, decoupling from the UI isn't as big of a deal. At some point in the future, should we feel the need, there is nothing to stop us from peeling off the Presentation layer and replace it with a desktop UI, implemented using WPF. In this case, the Presentation layer is the UI. Alternatively, we can unplug the stack starting from the Application layer on down and put it inside a different web API, one that is specifically targeted toward mobile clients. Anything is possible.
In some of the other demo solutions I studied, the web API project was treated as the Application layer. I don't agree with this. My stance is to treat the Web API project as belonging to the Presentation Layer (as distinct from the UI). This coincides with the Taylor solution and provides for much better decoupling at an architectural level.
Common Layer Organization
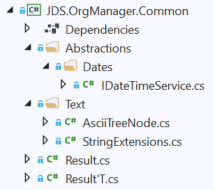
There isn't much going on here, just your usual cross-cutting concerns like text manipulation and the like. As always, be careful what you put into this layer and make sure that it's a cross-cutting concern.
Here's a short explanation of the IDateTime interface. This is in here because it's used by virtually every layer, including the Domain layer. The actual implementation for it is in the Infrastructure layer. This is something you might take for granted, but it is an incredibly powerful pattern. Some of the benefits are:
- All components and logic which are dependent upon the system date/time instantly become unit testable.
- What's more, if you have a system which is highly sensitive to the current date/time, you can put a special implementation behind this, and all subsystems will stay in sync.
- I'd take this further and put in the provision that all date/times must be in UTC across the whole stack, except when being presented to the user. The reasons for this are numerous, but suffice it to say, I've acquired this point of view after working on dozens of legacy systems which DON'T do this.
Unit Test Projects
When adding unit tests to a solution, I largely follow the conventions espoused by Roy Osherove in his book The Art of Unit Testing. For instance, the folder structure of unit test projects should mirror the folder structure of the projects under test, and each test should be cohesive and test only one thing. In terms of code coverage, 100% is rarely feasible or necessary. Aim to test the most critical pieces first. Test-driven development (TDD) is easier when using CQRS, and I may touch on that in a future post. If you've designed them well and are using dependency injection properly, then command/query handlers should be easily unit testable.
Points for Style: F# Projects
In the demo application I've added an F# project to the solution, representing specialized logic in the Domain layer for a bounded context. This is just to demonstrate how easy it is to create multi-paradigm solutions, and the way that I dovetail F# code into a .NET solution which is mainly built using C#. As stated in the blog entry on DDD, functional programming techniques are extremely powerful when used to implement domain logic. In this kind of a scenario, anemic domain models are okay, because the business rules are encapsulated inside functions. I'm not going to do a lot in the future using F# in the demo application, however a complete multi-paradigm solution would probably be comprised of 80% C# code, and 20% F# code. This gives you an idea of what's possible.
namespace JDS.OrgManager.Domain.HumanResources.Advanced
open JDS.OrgManager.Domain.HumanResources.Employees
open System.Linq
open System.Collections.Generic
type OrganizationVerifier() =
let rules = [
(fun (emp : Employee) -> emp.AssertAggregates());
(fun emp -> emp.VerifyEmployeeManagerAndSubordinates());
(fun emp -> emp.VerifyPtoHoursAreValid());
(fun emp -> if emp.FirstName = "John" && emp.LastName = "Doe" then raise <| new EmployeeException("Invalid employee name!"))
]
let rec verifyOrgRecursive (emp : Employee) =
rules
|> Seq.iter (fun rule -> rule(emp))
if not <| emp.Subordinates.Any() then
(1, emp.EmployeeLevel)
else
let sCount, sComp = emp.Subordinates |> Seq.map verifyOrgRecursive |> List.ofSeq |> List.unzip |> (fun (c, x) -> (Seq.reduce (+) c, Seq.reduce (+) x))
(sCount + 1, sComp + emp.EmployeeLevel)
interface IOrganizationVerifier with
override this.VerifyOrg(employees : Employee seq) = new List<int * int>(employees |> Seq.map verifyOrgRecursive) :> IReadOnlyList<int * int>
Example code for a domain class built using F#.
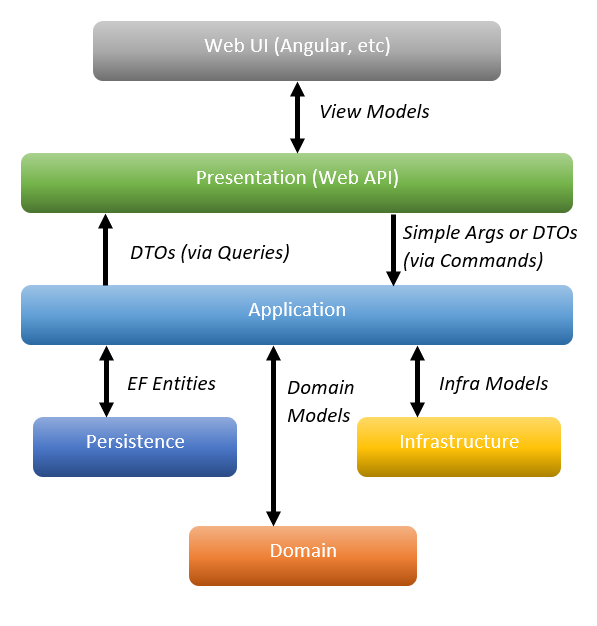
Layer Interaction
Simplistically, this demonstrates how the layers interact with each other.
Conclusion
In this entry I went into detail about how to implement Clean DDD and CQRS in a .NET Core solution. I mentioned some of the experts whose solutions I studied and spoke a little bit about some of their solutions. I presented the use case for a fictional company to create an organization management tool, and I introduced the demo application. I laid out some of the code-level conventions and project-level guidelines for organizing the solution, and I talked about functional organization vs. component organization. Finally, I went into detail about each layer of the architecture, building off the concepts presented in the previous blog entry. Finally, I introduced unit tests at a surface level, and I wrapped up by pointing the way toward building multi-paradigm solutions, which combine both functional F# code with OOP C# code.
Experts / Authorities / Resources
Robert C. Martin (Uncle Bob)
Roy Osherove
Jason Taylor
Julie Lerman/Steve Smith
Steve Smith
Jimmy Bogard
- Jimmy Bogard - Home
- LosTechies.com
- MediatR (GitHub)
Matthew Renze
Vladimir Khorikov
Greg Young
Dino Esposito
Microsoft - Microservice/DDD Guide
Code Maid
- CodeMaid - Home
- Using CodeMaid (YouTube)
Dapper
- Dapper (GitHub)
This is entry #8 in the Foundational Concepts Series
If you want to view or submit comments you must accept the cookie consent.