
A Basic Intro to Domain-Driven Design

Introduction
What is Domain-Driven Design? It is a software design methodology which seeks to efficiently create business logic components and functionality from business requirements, typically by working closely with domain experts. In this entry, I give a brief overview of Domain-Driven Design (DDD) and discuss its importance in modern software development. As before, I will periodically refer back to the demo application to elaborate on certain concepts.
Data-Centric vs. Behavior-Centric Applications
Domain-Driven Design was first articulated by Eric Evans in 2003 in his seminal book, Domain-Driven Design: Tackling Complexity in the Heart of Software. In a nutshell, he describes it as a methodology for tackling complexity in the heart of business applications (remember what I said two posts ago about managing complexity?). This means business complexity: that which is introduced of necessity by trying to model what the business actually does. Think, real world rules and objects of the business. This is important, especially in SaaS systems, because the business rules and processes represent the very problem that your solution is trying to solve.
Software systems of prior eras had a peculiar, and not especially user-friendly design: think a specialized technician punching numbers into a 1980's monochrome, text-based user interface and you get the picture. Indeed, there are countless legacy systems like what I described still in existence in any number of industries. These systems were usually architected by starting with the data model—in other words, the database schema—and user interaction logic was scaffolded on top. Business rules, such as validation logic or complex calculations, came second and were often tightly coupled to the data model (think business logic inside stored procedures in the database). Such data-centric systems, which emphasize user interaction directly with the data and place business logic in the back seat are referred to as Create-Read-Update-Delete (CRUD) applications.
From a Geocentric Model...
As requirements became more complex, new architectural styles such as 3-tier architecture evolved in response.
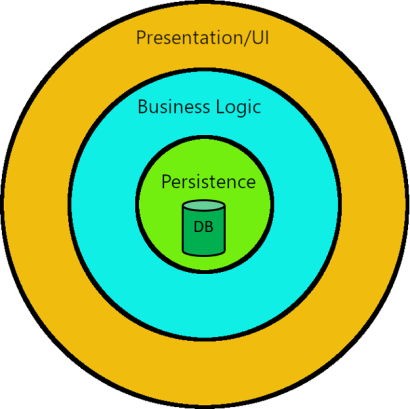
However, these models still maintained an underlying data-centricity with a database at the core of the application. The addition of a business layer didn't necessarily negate the fact that the database and data access layer remained the focus for design decisions and often guided the direction of the system, sometimes at odds with business requirements. In this respect, these styles of applications are analogous to pre-Copernican, geocentric (earth-centered) models of the solar system.
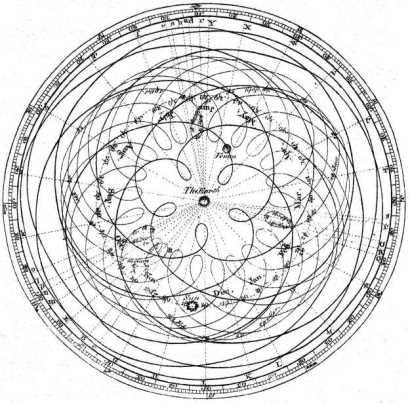
In the same way that the Ptolemaic model, with epicycles and whatnot, worked "well-enough" to predict the orbit of the planets, there was a more elegant model waiting to be discovered.
...To a Heliocentric One
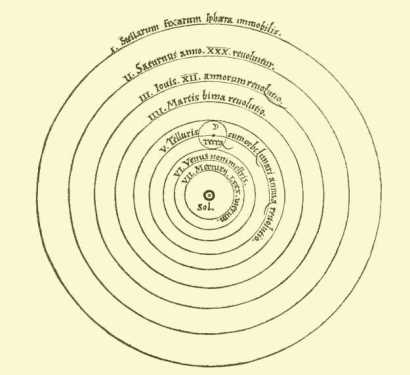
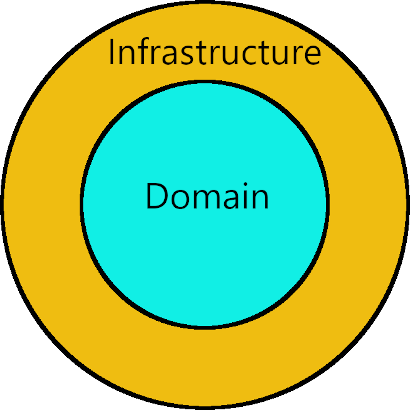
Domain-Driven Design is that model. In my opinion, DDD represents a paradigm shift, a Copernican revolution in software development in that it places the business domain first, just as a heliocentric (sun-centered) model of the solar system replaced the geocentric one. This contrasts with how applications have traditionally been built, which is to start with the data model (e.g. database tables) and build around that.
DDD is interesting because it seeks to model business processes first and foremost. At an extreme level this is accomplished through User Experience (UX)-Driven Design, in which business tasks are modeled starting with the user interaction and going down into the Domain layer (where the business logic lives). It's important to note, however, that DDD is NOT a first-class architecture on its own, but rather a methodology for communicating with the business team and translating business requirements into a business domain model. For that reason, it is typically combined with an actual architectural pattern, such as Clean Architecture, when building greenfield applications.
Objective: Decoupled Business Logic
Even if DDD is not a first-class architecture, you'd better believe that it still has a massive influence on the architecture of the system. One of the main objectives of DDD is to keep the business logic of your application separate from everything else and allow it to expand over time as business requirements are better understood, rather than scattering business logic throughout the application and then having to modify it. In this respect, it expresses the Open/Closed principle at an architectural level. You know you have accomplished this if you have a final architecture in which the libraries comprising the Domain layer, and all of the business logic contained therein, can be entirely unplugged from your software system and plugged into a different system.
An Evolving Methodology
Early on, DDD focused on the actual domain model itself, typically expressed through behavior-heavy, object-oriented (OOP) code. In recent years (post-2012) the concentration has shifted from OOP-style models to the modeling process itself, with a heavy emphasis on business domain expert involvement. For instance, Dino Esposito discusses event-storming in this Pluralsight course, which is basically a formal collaboration between the business and technical teams taking place over the course of multiple meetings. Such meetings have a distinctly "Agile" character to them, in that there are certain guidelines in place such as the "2-pizza rule" (limit the meeting to the number of people that can be fed by two pizzas, which is approximately 8), heavy use of whiteboarding and sticky notes, having a formal administrator, and so on.
Additionally, as technologies have changed in recent years, there's been a mind toward building the domain model using paradigms other than OOP. In particular, functional programming is proving itself to be extremely useful in modeling business rules and processes. I have a simple demonstration of how such an approach could be implemented using F# in the demo application. What's stayed the same is the emphasis on behavior.
Not a Silver Bullet
From the beginning, DDD never claimed and still does not claim to be a panacea—as I mentioned in a previous blog entry, there is never a silver bullet, no one-size-fits-all solution. Domain-Driven Design is most appropriate for certain types of solutions, more specifically, those that require a large amount of complex business logic operating under the hood. Once again, it is geared toward tackling business domain complexity. The experts I've studied generally agree that DDD is overkill for data-driven or CRUD applications. Conversely, it could be argued that CRUD applications are and have always been ill-suited for businesses, and that the users have been changing their behavior up to this point in order to work with the application, not the other way around. Whatever the case may be, you (as the architect) should evaluate the problem domain carefully before settling on a specific tool. Don't blindly use a DDD screwdriver if a CRUD hammer would suffice.
Software Concepts Which Are Relevant to DDD
These are a couple of concepts which are not specific to DDD, but which you should be aware of.
Immutability
This is the idea that once an object or instance of a data type is created, it cannot be changed. EVER. In order to "change" an immutable object you must create a copy of it, with the changes reflected in the new instance. Immutability is one of the cornerstones of functional programming, but it also plays a key role in DDD. In the .NET world immutability has less to do with whether something is a value type or a reference type, and more to do with the intent of the code. For example, System.String is your classic example of an immutable reference type. It's a heap-managed type just like other classes, but once you create a string, you cannot change it. Interestingly though, strings have value semantics, so you can perform operations against strings like cutting out a substring, making the string all uppercase, and so on, but those operations do not change the original string: they create a new one. I employ a similar approach in my interpretation of DDD. Immutability confers other benefits, such as having code that can more easily be checked for correctness, and the fact that immutable data structures are inherently thread-safe (if you can't mutate state then there's no need for locks). Philosophically, immutability is analogous to the Open/Closed principle, though applied at a much more granular level.
Idempotency
This is similar to immutability, except this relates to behavior rather than state. Idempotency is the idea that a given method or function always does the same thing every time you call it. As you can guess, idempotency and immutability go hand-in-hand, and it is likewise another cornerstone of functional programming. Methods or functions which operate only against immutable types are more likely to be idempotent, though there are obvious exceptions (like if you're generating a random number, etc.). Also, updating a value in a row of some database table might be an idempotent operation—you are just updating it to the same value over and over again every time you call the method. Idempotent operations are important because programming in this style tends to lead to code which is more understandable, maintainable, testable, and correct.
Basic DDD Concepts
Here is a non-exhaustive list of DDD-specific concepts, and a brief description of each. Where appropriate, I go into greater detail.
Problem Domain
This is the specific business problem the software is trying to solve. This is the all-encompassing view of the landscape. Your job is to understand the problem domain by communicating with the business team and applying DDD practices to build a domain model. As your understanding of the problem domain grows and you get a sense of how big it is, it may make sense to logically break it apart into smaller sub-domains.
Domain Model
The domain model maps to the problem domain. This is the comprehensive collection of entities, services, factories, and other technical products which are created during development and express the underlying business logic and processes. Think of this as the problem domain expressed as code.
Ubiquitous Language
As Eric Evans directly states: "translation is bad" [Domain-Driven Design Fundamentals]. This is another understatement, as my first hand experience has shown me time and again. I've worked on myriad systems with which I'm forced to create "decoder ring" documents that help me understand how software artifacts—database tables, classes, enumerated value types—map to real-world entities and also other software artifacts. Legacy systems that have been touched by numerous developers over several years can often resemble an archaeological dig, with different sections and layers exhibiting radically different coding and naming conventions, as well as patterns and practices. For whatever reason, there may not be any consistency in how objects are named. Is it Customer? Partner? Client? So on, and so forth. Suffice it to say, having to constantly shift gears and transit across these mental models creates a mental burden and sinks productivity.
The solution to this problem, and the bedrock of DDD, is the ubiquitous language, or UL.
Ubiquitous (adj.) - existing or being everywhere at the same time : constantly encountered : widespread
Merriam-Webster Dictionary
What is the ubiquitous language? It is a shared, consensus language which is used to communicate business needs to the technology team and provide feedback back up to the business. It is comprehensive enough that it can communicate both business and technical concepts in relation to the domain. It facilitates easy, seamless communication between the technology and business team. The UL is worked out by both the business and technical team in advance, before any development begins, and once established it is NOT changed, except by agreement from both teams. This last point is important, because failing to protect the UL results in exactly the problem I described.
Even more importantly, the nouns, verbs and other elements of the ubiquitous language which have been hashed out by the teams will permeate throughout YOUR ENTIRE ARCHITECTURE. All technical artifacts are expressed in the UL, and not the standard "CRUD" language that developers may be used to. For example, for a shopping cart system the UL may dictate that orders are "processed." Therefore, the corresponding controller method should be called ProcessOrder(), not CreateOrder(). Database tables, columns, etc. should reflect the UL, as should namespaces, class names, and everything else in the stack. A corollary of this is that any agreed upon change of the UL will result in a MANDATORY refactoring of the code base, no questions asked.
Another point to understand is what the ubiquitous language is not. It is NOT the native language or jargon of the business, but rather an agreed-upon middle ground between the business and the technology team. In that respect, it resembles "pidgins" derived from human languages. Remember, the goal is to facilitate communication between two (or more) groups of people who have entirely different mental models and domains of expertise, not to be 100% correct in the usage of one team's vocabulary.
Bounded Context
A bounded context (BC) is the technical representation of a sub-domain. Think of it as a logically bounded area of the solution space which maps to a clearly demarcated area of the problem space. In other words, it is a logical sub-section of the domain model with clearly defined boundaries. According to Evans, the "bounded context is an essential ingredient." I would argue that it is THE essential ingredient.
Bounded contexts emerge from a growing awareness of the business through discussions using the ubiquitous language, and they often map to a specific area of the business. For example, in the demo application each department—Accounting, Human Resources, Operations, etc.—map to a separate bounded context. This is one of the most common uses of bounded contexts.
From a design perspective, bounded contexts should abide by the Single Responsibility principle and each can stand alone, as it represents a self-consistent area of business logic. In a .NET solution, it makes sense to break these apart into separate folders, projects, or clusters of projects which are identifiable by namespace. The demo app clearly shows this. This "pluggability" is important, because a given BC can then be moved into its own microservice later, if warranted. Without getting too far ahead, I want to also emphasize that this logical separation occurs AT EVERY LAYER of the architecture.
Now, what's interesting is that Eric Evans recommends keeping the data for entities in different bounded contexts in separate databases. The benefit to doing this is that you have hard data isolation, and it makes it easier to maintain the boundaries between the BCs. Furthermore, different teams can work on each bounded context without stepping on each others' toes. This is rarely achievable in the real world (I haven't seen it), and if you're a SaaS startup you're probably trying to keep costs low and your solution simple, which means keeping your data model consolidated in one database. Conversely, you could theoretically use resources such as elastic database pools if you really wish to go this route. As with many design decisions, this one depends, but I tend to lean more toward having a single data store for each application.
Domain Entity
The domain entities are the core entity types of the domain model, which exist inside various bounded contexts. These are DDD representations of real-world objects. For instance, in a company management application (like the demo app) you may have an Employee entity which contains the data and validation logic to represent employees of the organization.
Under the OOP-style of DDD, much of the business logic goes inside of the domain entities, though Eric Evans warns about going too far and having "bloated entities." If this is the case, some of the logic can be delegated to the value objects (discussed below) which comprise the entities.
What's important to understand is that domain entities have no intrinsic identity. You cannot know the identity of a domain entity by examining its data properties. This is an important point. For example, the demo application may allow two different employees that are named John Jacobs. For this reason, domain entities require a key property, typically an integer or GUID (globally unique identifier). Note that this is a different concept from primary keys in a database, although sometimes they align. As Evans states, "an entity shouldn't even have an equality comparison." In other words, they have reference semantics.
Whether or not to use GUIDs or integers for the entity ID, or some other data type, really depends on the situation. There is no hard and fast rule on when each is appropriate, but here are some considerations:
- GUIDs are useful because they can be created anywhere in the stack, and still be guaranteed to be unique. My opinion is that these are better in heavily business-centric applications, in which you might have complex business components that are creating domain entities based on some workflow or automated process.
- Integers are useful because they come off as more natural, are less heavy to persist in a database (which can make a huge performance impact if you have millions of rows), and they are more traditionally used as keys in databases and other backing stores. My opinion is that these are better suited to applications that are built using DDD but may lean a little bit more toward the CRUD end of the spectrum. For instance, if you have an application in which domain entities are generally created by users or user workflows, then persisted to a database after going through some business logic, then these may be perfectly okay.
Something else to mention is that these should be immutable to the greatest extent possible that your design allows, without causing too much pain in other areas (i.e. mapping from one type of model to another). This is another design trade-off between flexibility and robustness. In .NET there are different ways you can enforce immutability. I've listed a few of them in order of most robust/least flexible to least robust/most flexible:
[Update as of : Please note that my guidance on the following has changed with the introduction of important language features of C#9, notably, init-only setters. I discuss this more in-depth in my blog entry on entity mapping strategies.]
Read-only auto-properties (C#6) - this is the most immutable you can get. Once the properties are set in the constructor and/or property initializers, there is absolutely no way you can change them.
public DateTime DateHired { get; }Private setters; public getters - the properties can be changed inside the class but not outside of it in ordinary code. Private setters can, however, be set from the outside using reflection. This is useful, because it allows mapping tools which use reflection under the hood to set our properties for us automatically, while keeping us on the happy path the rest of the time.
Think of this as a middle road which is "immutable enough" for our purposes, so this is the approach that I'm using.(Now using init-only setters. See below.)public DateTime DateHired { get; private set; }Internal setters; public getters - this is basically the same as the approach above, except that you can set properties from other classes within the same assembly (or friend assemblies). This could be useful if you're using factories to generate your domain entities instead of constructors and/or mapping tools. Likewise, it could work well using the Builder design pattern.
public DateTime DateHired { get; internal set; }Public getters and setters; immutability enforced through convention - you leave your properties open to modification and then "promise" yourself that you will never modify them after their initial creation. Even if you're OCD enough to actually pull this off, the next person to touch your code won't be. Your code base will devolve into spaghetti code, and you will lose all the benefits that true immutability would have conferred. For that reason, I don't recommend this.
public DateTime DateHired { get; set; }Init-only setters (new with C#9). This is the language feature that I was waiting on for so long. It allows us to create immutable Domain entities without leaning on constructor initialization, but rather the simple and elegant property initialization syntax that we all know and love. THIS is the approach that I'm using.
public DateTime DateHired { get; init; }
One last point is that domain entities in separate bounded contexts may have the same name and refer to the same real-world objects. However, these entities should differ from each other in that each one only exposes the data properties and business logic that it needs to fulfill the requirements of each bounded context. I've tried to demonstrate this in the demo app by creating Employee entities in two separate bounded contexts—one for Accounting and one for Human Resources. The Employee entity in the Accounting bounded context doesn't care about many of the properties of the HR version—it just needs data and logic to process payroll, etc. A corollary is that having properties on domain entities which are ignored for all purposes in a given context is a huge design smell. Related to this is reusing domain entities as persistence entities, which I will get into a future blog entry.
Value Object
What are value objects? I define them as representations of complex problem domain values, as opposed to entities, which represent real-world things. Think of these as simple pieces of data which require a little more than what your native programming language (C#) offers out of the box, and which are more specific to the problem domain you are trying to solve. Some common examples would include zip codes, Active Directory accounts [Taylor], addresses, states, money, date/time ranges, measures, etc.
As Taylor states, you should "prefer these over primitive types where it makes sense." Value objects are more complex than primitive types, but they carry a lot more semantic information. Think about it, what code is easier to maintain?
- A method which sets some variable to 5, the implication being that this represents a dollar amount, OR
- A value object which has both amount and currency properties, and unambiguously represents "5 dollars"
Jimmy Bogard, the creator of MediatR, has a good discussion about value objects vs. primitives here.
Some other considerations of value objects are:
- They should be small and absolutely immutable (i.e. implemented using read-only auto-properties in C#).
- Their identity is represented by the combination of their essential data properties. There should be NO identity property whatsoever—no GUID, no integer, nada. Furthermore, these should have an equality comparison implementation which is based on those essential data properties, e.g. "5 dollars" == "5 dollars".
Value objects are extremely important and represent the lowest-level building blocks of a DDD application. According to Evans, these a good place to put logic ("classic software logic"). I concur. Since value objects are immutable, they play nice with functional-style code and it's easier to write unit tests against them. It makes sense to put validation logic into these, such as checking to see if a zip code is valid, etc.
As you may have guessed, value objects have value semantics. However, this does NOT necessarily mean that you absolutely must implement them as .NET value types in your application. To get a sense of what I mean, notice how System.String in .NET is a reference type which has value semantics. I use value objects in the demo application in a similar way.
Finally, domain entities may "have" value object properties. However, a value object by definition may never be composed of domain entities, but only other value types and primitives.
Aggregates
Aggregates are clusters of domain entities that operate as a cohesive, functional whole. These are "another way to reduce complexity" [Smith]. Think of an aggregate as a tree of connected objects which grows downward. The object at the very top of the tree is the aggregate root.
The aggregate root is critically important, because it is the reference point for the entire object graph comprising the aggregate. When you perform operations against the aggregate, you may only do so via the aggregate root. Also, the aggregate root is important for enforcing invariants: conditions which must hold for the system to be in a consistent state. It maintains consistency of the entire aggregate. Logically, it follows that aggregates must be modified, persisted, and so on transactionally via the aggregate root. An acronym to describe this is ACID [see Wikipedia]:
- Atomic - The aggregate and all its constituent parts are committed to a database entirely as a single transaction, or the operation fails entirely. There should never be a situation in which part of an aggregate is committed and the rest isn't.
- Consistent - Any transaction against the database always leaves the database in a valid state, with all invariants intact.
- Isolated - No transaction can interfere with any other transaction. Concurrency is ensured.
- Durable - A committed transaction stays committed, even in the case of a system outage.
There are some design considerations to keep in mind when defining aggregates. One heuristic you can use is the Rule of Cascading Deletes, which asks the question, does it make sense to delete all the child objects of the aggregate when you delete the aggregate? If the answer is no, then you are really dealing with multiple aggregates and need to rethink the boundaries that define each of them. Additionally, when identifying the relationships between the entities that make up each aggregate, Evans recommends that you use unidirectional relationships instead of bidirectional ones. Once again, I think this is some sage advice, and I would further add that unidirectional relationships are a good idea anyway, whether or not you're practicing DDD, because cyclical object graphs in your code adds complexity and can mess with serialization components, among other issues.
Finally, aggregates are also important in the layout of the solution, because it is common to create a separate folder/namespace for each.
Domain Services
Not a lot needs to be said about these. Domain services are useful for building out important operations that don't naturally fit into a domain entity or value object. They typically provide a higher-level orchestration between multiple domain entities and/or value objects. Domain services should be stateless; however they may have side effects. In general, you should strive to put business domain logic inside domain entities and value objects first, before falling back on using domain services.
Domain Events
Domain events are useful for communicating between aggregates or coordinating complex business logic. The importance of domain events is that they decouple the behavior of an action from whatever triggered it. They are also good for creating extension points for your application, which is the use case that I'm most keen on. In this regard, they help make it easier to extend your domain model without violating the Open/Closed principle. Some other important considerations for domain events are:
- These are encapsulated as objects (do not use .NET events for these).
- They are almost always immutable.
- They represent the past and are therefore always named for something that has already happened, e.g. EmployeeRegisteredEvent.
- Since they represent something that happened, they cannot be canceled, stopped, modified, etc.
Including a DateTime property representing the date and time that the event occurred inside the base class for all your events is a really good idea. I recommend that you use UTC for this (and all other internal date/times as well). Also, some of the experts I've studied recommend using the Singleton design pattern for a dispatcher class to raise events. Lerman/Smith go further and say not to inject anything into domain services, objects, etc. I partially agree with them, so my solution uses a nimble way to inject internal messaging components into the event dispatcher and then expose it to domain entities via a static property. This way, there's no need to worry about using dependency injection in domain entities and services.
Shared Kernel
The shared kernel is part of the domain model that is used across bounded contexts, and possibly even separate teams. Most importantly, teams agree not to change it without collaboration. In my interpretation, this is a common library within the domain layer, which houses generally reusable domain components such as Address, ZipCode, Money, etc. Note that this is distinct from the global common library (or libraries) for the entire solution, which houses globally cross-cutting concerns, like logging, exception-handling, text manipulation, etc. As with any kind of common library, beware of the One Ring of Power anti-pattern, in which you bloat it with components and classes that belong elsewhere. Be judicious in your designs, and don't use common libraries as dumping grounds for code that can be better organized in another place in the solution.
Repositories
The Repository pattern is a pretty well-established and common pattern. The purpose of this pattern is to abstract away read/write operations against the underlying data store (database) of your application. This is typically done by injecting an interface for your repository into the business classes which need to persist or read data from the database. In this way, the implementation details of the underlying data store are hidden from the business code which depends upon the repository interface. As Julie Lerman states, "[Repositories] allow you to design your domain the way you want it to be without worrying about persistence details." In theory, the implementation of the repository could be anything—a relational database, Azure table storage, whatever. Repositories can also be injected into each other, thus implementing the Decorator pattern, which is a way to insert cross-cutting concerns into calls to the underlying data store.
I've used this pattern countless times in systems that I've architected from scratch and also in legacy systems that I've had to maintain. In a future blog entry, I'll make an argument why the repository pattern isn't necessary in modern applications, and sometimes can even add unnecessary complexity. If you choose to use the repository pattern in your DDD applications, then the experts such as Lerman/Smith, recommend using them in the following way:
- You should have a separate repository for each aggregate.
- Repository operations should operate only against aggregate roots.
There are a few common repository blunders you should watch out for, which may also apply to other persistence patterns, especially if you are using an Object Relational Mapper (ORM). Here are the most common ones:
- N+1 query errors.
- Inappropriate use of eager or lazy loading.
- Fetching more data than what is required.
Factories
These create new objects, as opposed to repositories, which work with existing objects. Various factory patterns have been discussed at length by the Gang of Four, and this is basically just a variation on that theme. In DDD, the purpose of factories is to abstract away the process of creating and initializing new domain objects. For example, you might want a factory to create new Employee entity instances based upon some configuration data. Mapping classes are also examples of factories.
In my opinion, these may or may not be necessary, depending on how complicated your constructors are, and whether you choose to use a different creational design pattern, such as Builder. Another approach is to implement a series of fluent syntax methods to build up domain entities. I have an example of this in the demo app.
Rich Model vs. Anemic Model
In a rich domain model, domain entities are behavior-rich and encapsulate a large portion of the business logic. In an anemic domain model, domain entities only encapsulate data and are basically bags of getters and setters. Under orthodox DDD, you should aim for a rich domain model rather than an anemic one, which is to say, you use your domain entities and value objects for much more than just holding state. These also include business and validation logic.
What's interesting is that when DDD was first developed, back around 2003, anemic model was considered to be an anti-pattern and the focus was on putting domain logic into the domain entities themselves. See this blog post [Martin Fowler] for background. Now, over 15 years later, anemic model could be acceptable under some circumstances, such as when using functional programming languages to build the business domain. This is part of a much wider discussion, so I encourage you to go out and do more research on this.
Anti-Corruption Layers
This topic is more pertinent to brownfield development, so I'm not going to go into detail on this. Essentially, an anti-corruption layer is like the GOF Adapter pattern, except it applies on an architectural level. It is comprised of several design patterns, and it acts like a layer of protection and translation between your (hopefully well-architected) domain model and some legacy system. Its name is exactly what it means: it prevents details from the legacy system from leaking into your pristine domain model (i.e. corrupting it). Note that this is important, regardless of the quality of the legacy system, because "even when the other system is well-designed, it is not based on the same model as the client." [Evans]
Conclusion
This concludes my brief introduction to domain-driven design. In this blog entry I discussed the paradigm shift that occurred, and is still in progress, as software applications become less data-centric and more behavior-centric. DDD is one approach to building applications which focuses on the processes and behaviors of the business, rather than data, and emphasizes modeling the business domain first. I discussed various DDD concepts in brief and talked about their usefulness in building modern applications. Once again, I emphasized that DDD is not an architecture in and of itself but is rather a methodology for modeling and controlling business complexity in the heart of the system. In future blog entries I will build on these concepts as I introduce first-class architectural approaches to building applications on the ASP.NET Core stack.
Experts / Authorities / Resources
Eric Evans
Vaughn Vernon
Lerman/Smith, w/ Eric Evans
Jimmy Bogard
Dino Esposito
Martin Fowler
Jason Taylor
Cesar de la Torre, Bill Wagner, Mike Rousos
- .NET Microservices: Architecture for Containerized .NET Applications
- Tackle Business Complexity in a Microservice with DDD and CQRS Patterns
This is entry #6 in the Foundational Concepts Series
If you want to view or submit comments you must accept the cookie consent.